Defensible Security Posture – Part 2
January 31, 2014 5 Comments
Defensible Security Posture – Part 2
Defensible Security Posture – Part 1
How can you leverage the Defensible Actions Matrix? A defensible actions matrix defines processes and procedures that can impact an attacker’s capability at various stages of the cyber kill chain.

Cyber Kill Chain
In Defensible Security Posture – Part 1 we introduced the concept of the Cyber Kill Chain. As a recap, a “kill chain” describes the progression an attacker follows when planning and executing an attack against a target. Understanding the signature of an APT helps align defensive capabilities, i.e., to identify security controls and actions that can be implemented or improved to detect, deny, and contain an attack scenario.

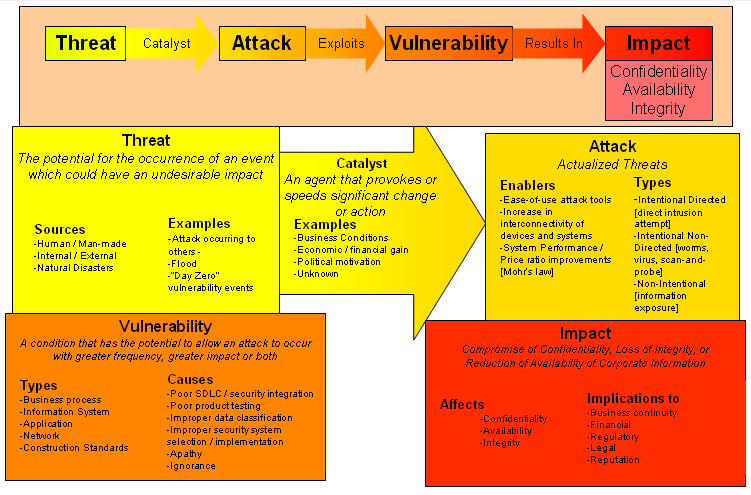
The APT Signature and Cyber Kill Chain
A complex incident may involve multiple kill chains with different objectives that map to various phases of the attack. For example, reconnaissance is performed to assess target feasibility to develop an attack plan. Attackers may also perform further reconnaissance after gaining an initial footprint into the internal network to revise strategy for lateral movement and persistence.
Defensible Actions Matrix
In this Defensible Security Posture – Part 2 blog we provide a case study that makes use of the Defensible Actions Matrix and offers some defensive practical best-practices. The basic idea of a Defensible Security Posture is that you aren’t striving for an absolute, but rather for a position (or posture) that is able to be defended even when it’s infiltrated. Common factors associated with APT attacks include the following:
- Sudden increases in network traffic, outbound transfers
- Unusual patterns of activity, such as large transfers of data outside normal office hours or to unusual locations
- Repeated queries to dynamic DNS names
- Unusual searches of directories and files of interest to an attacker, e.g., searches of source code repositories
- Unrecognized, large outbound files that have been compressed, encrypted password-protected
- Detection of communications to/from bogus IP addresses
- External accesses that do not use local proxies or requests containing API calls
- Unexplained changes in the configurations of platforms, routers or firewalls
- Increased volume of IDS events/alerts
The more detailed Detection Framework, presented in APT Detection Framework is used to analyze the potential attack scenarios based upon a threat/risk profile to more definitively identify the above factors, as well as any detection gaps while the Defensible Actions Matrix summarizes it based on actions/controls.
The following example depicts a sample actions matrix using the actions of detect, deny, disrupt, degrade [optional], deceive [optional], and contain. Documenting the capabilities defenders can employ in this matrix as a worksheet enables organizations to quickly assess their Defensible Security Posture as well as identify any gaps or needed compensating controls.

Example Defensible Actions Matrix
Evolving Industry Best-Practices
In order to provide a foundation for the Defensible Actions Matrix we offer a sampling of defensive APT-aligned practical best-practices as an example. These will be expanded upon as a more complete APT Best-Practices framework and evolution in future blogs.

Organizations should use a comprehensive programmatic approach, no one single technology will stop advanced attacks, even products specifically targeted at advanced forms of attack. Ongoing integration and sharing of security intelligence among disparate security
technologies and other external organizations should be a security program goal (see: APT Threat Analytics).
As such, organizations should review existing technologies and increasingly utilize advanced features in the latest products or services to keep up with changes in the threat landscape. This should be performed with the mindset of integrating and unifying security processes between each technology so that effective coordinated response to threats is possible and the detection and reduction of breach events is the result.

Social Media and Information Sharing: Attackers often leverage publicly available information on websites and social media to find information about an organization that can be useful in planning an attack. Information sharing and social media policies should define how material should be handled and exposed via public channels.
Configuration Management: Configuration standards define templates to consistently configure applications and systems based on role, hardening them, removing un-necessary services and, eliminating defaults. Define processes that are enforced with change control for infrastructure integrity to limit the ability of attackers to exploit infrastructure to deliver malicious software to targeted systems.
Privileged Access Management: Organizations face significant security exposure in the course of routine IT operations. For example, dozens of system administrators may share passwords for privileged accounts on thousands of devices. When system administrators move on, the passwords they used during their work often remain unchanged, leaving organizations vulnerable to attack by former employees and contractors.
Organizations should grant user and system accounts leveraging role-based access the least amount of privilege needed to perform the job. Processes to create, audit, and remove accounts and access levels should be well-defined.
Shared Service Accounts: Organizations should ensure that service accounts, including default credentials provided with third-party software, are properly secured with defaults removed and provided only to those who need them to perform their job function.
Database Account Security: Organizations should manage and audit database accounts as part of a larger account management process. This includes ensuring that accounts are only granted the necessary level of access. Many organizations do not fully leverage the security built-in to databases and DBAs often use default admin accounts and users have full admin rights.
Two-factor Authentication: Two-factor authentication mechanisms is increasingly mandatory for networks or zones with critical data and/or servers. It can reduce the effectiveness of password stealing and cracking attempts.

Threat Intelligence: A threat intelligence capability leveraging internal and/or external sourced visibility can provide an indication that threat actors are focusing on specific types of attacks and indicators to detect these attacks. For more information see APT Threat Analytics.
Network Zones / Segmentation: Limiting and intelligently managing communications between services and systems on an organizations network helps contain an infection or compromise to keep malware or a persistent threat from running rampant. Ensure proper zoning and segmentation is performed in your internal network environment not just the DMZ and that proper firewall logging and inspection is performed between high- and low-security segments. Treat every system as untrusted. For more information see Adaptive Zone Defense blog.
Advanced Threat Protection: Evaluate and deploy a network-based advanced threat detection/prevention technology to reduce the potential impact of zero-day malware and other targeted attacks. Review existing advanced threat detection/prevention technology and ensure that the prevention capabilities are validated, tested and fully leveraged.
Context-Awareness: Evaluate and leverage context-aware security capabilities of security platform providers. Security platforms must become context-aware — identity, application, content, location, geo-location and so on — in order to make better information security decisions regarding APTs.
Firewall Rules/ACLs: Review and, if necessary, adjust ingress network firewall rules on a regular basis in order to ensure only critical inbound services are permitted to enter the network. This also includes geographical blocking or filtering at the country level where possible based on business need. For more information on Firewall Rule Lifecycle Management, see Security Program Best-Practices – Part 5.
Egress / Outbound Filtering: Egress filtering enables a managed perimeter with a focus on well-defined outbound policy. It declares the acceptable protocols and destination hosts for communication with internal systems, with a focus on any systems with critical or regulatory data, such as PII, ePHI, PCI and so on.
Network activity associated with remote control can be identified, contained, disrupted through the analysis of outbound network traffic implemented through open source software tools.
Remote Access / VPN: Implement internal inspection devices, such as intrusion prevention system (IPS) and network behavior analysis (NBA) technologies between any VPN termination device and the internal network environment so that attacks or behaviors can be discovered or prevented within the remote access network infrastructure.
DNS Sinkholes: A DNS-based sinkhole monitors for name resolution attempts of known malicious or suspicious domains. The resolution response is modified to point to an internal sinkhole server where the malicious or suspicious traffic is routed for further analysis and containment. In addition block “uncategorized” web sites at proxies, employ split‐DNS and split‐routing where possible.
Network IPS: Network intrusion prevention systems (IPS) can actively block network traffic matching patterns associated with malware command-and-control (C2) communication and data exfiltration. Review NG-IPS features and ensure it provides host and traffic anomaly detection (for example, using processing NetFlow data) and has capabilities to prevent or at minimum detect and alert on the anomalous traffic exiting through your perimeter devices.
Network IDS: A network intrusion detection system (IDS) can identify traffic patterns matching network-based scanning, malware C2 mechanisms, and data exfiltration. For more information see: APT Detection Indicators.
Network Security Monitoring: Validate that monitoring controls are in place and appropriate levels of logging are performed off-device in centralized log servers. Deploy security information management systems so that attacks can be detected or analyzed through additional analysis or correlation of incoming events.
Make sure that network visibility extends into virtualized environments either by tapping internal virtual switch traffic out for external inspection or by virtualizing IPS capabilities and running directly within the virtualized environment.
Form a Security Operations Center (SOC) or designate specific individuals to operate as a security operations center in order to properly monitor and respond as well as perform initial triage status for security events. When suspicious anomalies or alerts are received by the security operations center, invoke the incident response process.
Incident Response: Organizations should have a response plan for handling incidents as well as periodically review and test the plan. For more information on response readiness and preparedness please see APT Response Strategy.

Web Application Firewalls: Review Web application firewall configuration and implement vendor-recommended prevention settings. Prefer application firewalls that have the capability to share intelligence via reputation feeds, offer fraud detection services, and offer the capability to perform browser and endpoint security and spyware infection assessment.
Endpoint Protection: Host-based malware protection solutions including antivirus software, host intrusion prevention systems, and advanced malware protection solutions help identify, alert and block malicious software.
File Integrity Monitoring: File integrity monitoring involves monitoring system files for unauthorized changes and is often deployed as part of a larger software change management process.
Application Whitelisting: Application whitelisting defines a limited set of software that can be run on a system. Application whitelisting requires continual management of the list of allowed software to keep up with application and operating system updates.
Data Loss Prevention (DLP): Data loss prevention solutions use information tagging, packet inspection, and network monitoring to identify the potential movement of sensitive data outside the network. In addition, organizations can implement policies to manage the use of removable storage devices such as USB to limit these devices being used to steal sensitive information.
Security controls can have various impacts based on their purpose and implementation. Ultimately, the goals of a security control is to detect malicious activity, deny the malicious activity access to targeted assets, disrupt malicious activity that is actively in progress, or contain malicious activity to an area where damage can be mitigated.
The matrix illustrated below provides a partial example worksheet, applying the above best-practices and organizes the controls according to whether their primary goal is to detect, deny, disrupt, or contain.

Best-Practice Defensible Actions Matrix Use Case [Partial]
Conclusion
Recent incidents clearly demonstrate that cybercriminals can conduct operations that involve intrusion, lateral movement, and data exfiltration in complex networks secured to current best-practices. Attackers can adapt their attack techniques to the unique circumstances of targeted environment.
This level of resourcefulness points to the realization that current best-practices and regulatory compliance are a necessary minimum baseline but are not sufficient alone. Today there is an increasing need for organizations to progressively evolve and advance from current security posture to a more defensible and advanced program with visibility, validation and, vigilance.
Our solution, and the prime basis for this site, is to adopt a security architectural and design foundation approach that compartmentalizes breaches into small zones on networks and on endpoints. To strategically leverage the Adaptive Zone Defense blog to develop an innovative architecture with well-organized applications and services, managed communications and – good visibility to flows and logs that can actually detect the cyber kill chain activity and stop the breach.
It requires an ongoing lifecycle process to take the legacy, rapidly deployed and the chaotic infrastructure on the edge (innovation) and consolidate it into the core foundation based on the architecture/design blueprint, while continually evolving the blueprint based on new business requirements, technology solutions and, regulatory requirements, for more information see: Adaptive Security Lifecycle.
Coming Soon
In this series we will discuss advanced APT-focused best-practices that enable organizations to take their security to the next level and build from Basic to Augmented through to APT-specific Countermeasures to Advanced Security depending upon various factors including assets and threat/risk profile.

Evolution Lifecycle using Security Best-Practices
In the upcoming APT Operational Maturity and APT Intelligent Operations blogs we will also discuss the need for a continuously evolving next-generation SIEM, risk management processes and, network behavior anomaly detection that enable organizations to take security operations and situational awareness to the next level, depending upon various factors including threat/risk profile.

References
This Defensive Security Posture – Part 2 blog is also a part of the APT Strategy Series and Security Architecture Series. For a complete listing of all NigeSecurityGuy blogs see the Security Series Master Index.
Thanks for your interest!
Nige the Security Guy.